기존 아이디어 였던, Python Server 를 이용한 방법에 대해 팀원들과 회의 해 본 결과,
1. Python Server 만을 위한 ec2 추가 할당 및 설정에 대한 이슈
->한 기능만을 위한 서버 할당은 리소스 낭비 아닐까?
2. S3 bucket 에 파일로 저장하는 것에 대한 이슈
-> 간단한 파일을 읽어오기 위해 입/출력 기능을 사용해야 한다
3. 오픈소스 라이브러리에 대한 의존도 이슈
-> 오픈소스 인 만큼 예상치 못한 장애에 대한 대처가 힘들 수 있음.
해당 이슈들 때문에, 검색 키워드를 파일로 저장하고 이를 SpringBoot 에서 읽어오는 방법 보다는 다른 방법을 채택하기로 하는게
더 좋을 것 같다는 결론에 도달하였다.

파이썬 서버와 AWS 를 사용하지 않으면 상대적으로 더 간단하게 구현 가능하다.(내 생각)
파이썬도 사용해보고, Java의 WatchService API 를 이용해서 파일 변화 감지 기능을 만들어 보는 것도 흥미로운 발상이였지만,
간단하고 최적화 되어 동작하는 방법이 나중에 설명하기도 쉽고 유지 보수하기도 쉬울 것이라 생각한다.

1. 키워드 검색에 대한 검색량 데이터 찾기
어떻게 특정 키워드에 대한 검색량을 가져올 지 고민하던 도중, 팀원 한 분께서 추천해주신 SerpAPI 라는 사이트에 들어가게 되었고, 이 사이트에서 Google 의 검색 API 를 제공한다는 것을 알게 되었다.
무료 구독의 경우 월 100회 API 호출(searches) 이 제공된다고 나와있으며, 다양한 요금제들을 판매하는 것으로 보아, 오픈소스 라이브러리를 사용하는 것 보다, 좀 더 안전하게 API 를 호출하고, 사용할 수 있을 것 같다는 생각이 들었다.
현재 진행중인 프로젝트가 단순 기능 구현과 학습 목적도 있지만, 대부분의 팀원분들이 실제로 서비스를 사용자에게 제공하여 운영, 유지하는 것을 목표로 하고 있기 때문에, 기능이 안정적으로 동작해야 해서, SerpAPI 를 이용하기로 했다!

일단 API key 가 있어야 우리에게 무언가를 제공해줄 것이기 때문에 가입을 하도록 한다.
가입 절차는 간단하지만, 가입 후 email 인증과 휴대전화 인증 두개를 모두 완료해야 API key 가 발급된다.


가입이 완료되면 어떤 서비스를 이용할 건지 묻따(묻지도 따지지도 않고) API key 를 발급해준다.
이제 어떻게 요청문을 보낼지 정보를 보기 위해 Documents 페이지에 접속한다. 접속해보니 상당히 많은 검색 API 를 제공하고 있었다.
Google Search API는 Google 검색 결과를 스크레이핑할 수 있는 기능을 제공하고
Google Trends API는 특정 키워드의 검색량 변화나 트렌드를 분석하는 데 유용하며, 검색량 증가율에 대한 정보를 제공 한다.
따라서 칵테일 키워드에 대한 검색량 변화를 제공하는 Google Trend API 를 사용하기로 한다.
2. Spring Boot Project 에서 API 요청하고 응답받기
2-1. SpringBoot Project 에서 Json Parsing을 위해 Jackson 의존성을 추가해준다. ( 응답으로 오는 문자열을 가공하기 위해 )
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'com.fasterxml.jackson.core:jackson-databind'
//기타 다른 의존성들...
}
2-2. Documents 에 있는 내용을 참고하여 요청문을 만드는 메서드를 서비스 클래스에 만들어준다.
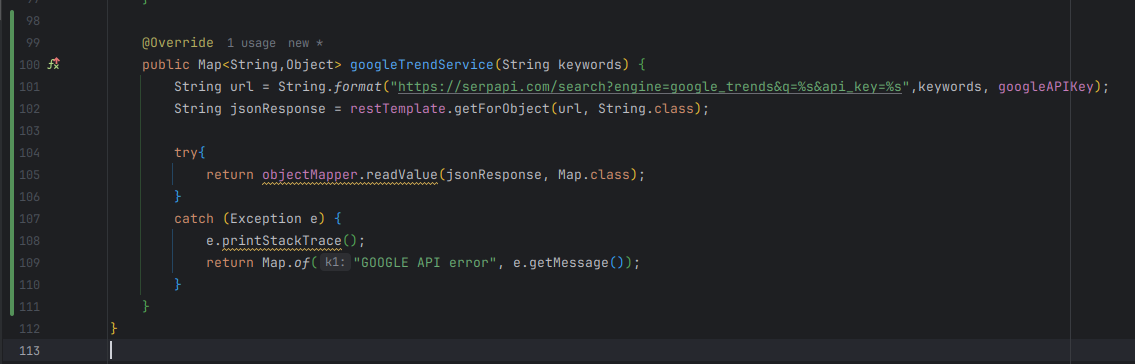
* 리팩토링 및 공통 에러처리는 일단 다음에!!!
2-3. API 요청을 처리하는 컨트롤러를 작성해준다 (앤드포인트를 만들어준다)
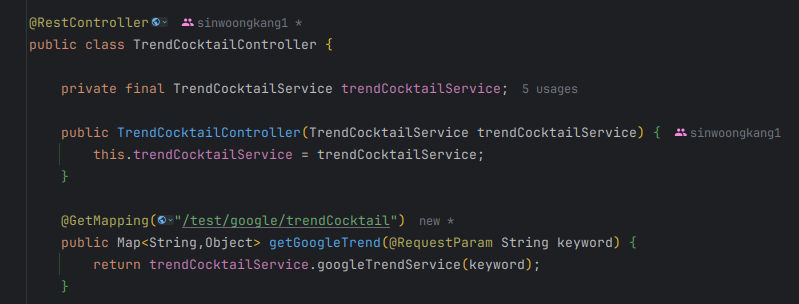
2-4. Swagger 를 통해 특정 키워드를 입력하고 요청이 제대로 오는지 확인해본다.

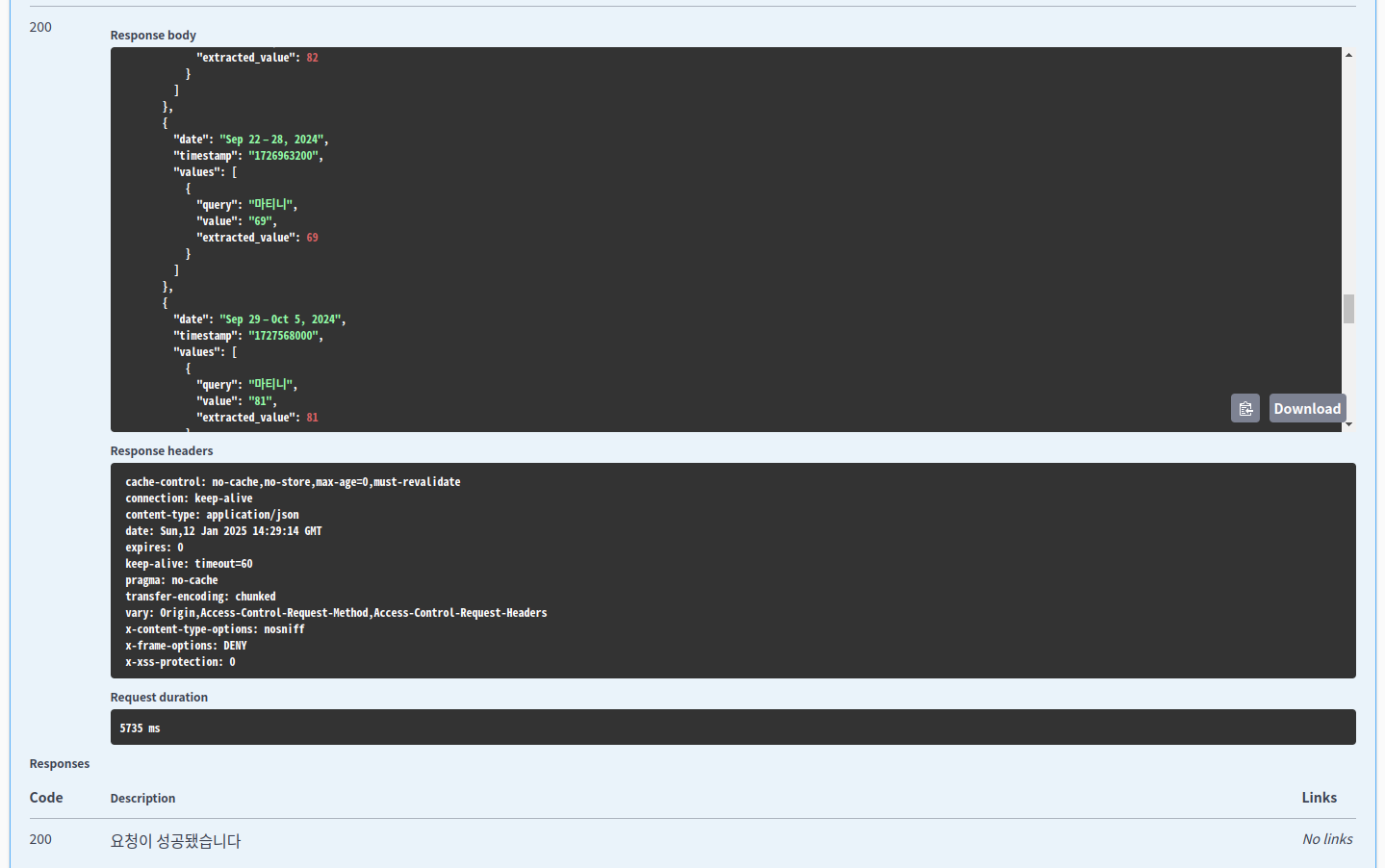
요청이 성공했고, 샘플로 요청한 "마니티" 키워드에 대한 정보들이 보인다.
응답에 대한 구조들은 아래와 같다.
데이터 구조
search_metadata: 검색 요청에 대한 메타 정보.
id: 고유한 검색 ID.
status: 요청 처리 상태. "Success"로 표시.
json_endpoint: 이 검색에 대한 JSON 응답을 확인할 수 있는 URL.
created_at: 요청이 생성된 시간.
processed_at: 요청이 처리된 시간.
google_trends_url: Google Trends 웹사이트에서 직접 확인할 수 있는 링크.
total_time_taken: 요청 처리가 소요된 시간.
검색 파라미터
search_parameters: 요청에 사용된 파라미터에 대한 정보.
engine: 사용된 API 엔진, 여기서는 "google_trends".
q: 검색 키워드, 여기서는 "마티니".
hl: 언어 코드, 여기서는 "en" (영어).
date: 검색 기간, "today 12-m"은 최근 12개월 동안의 데이터를 의미.
tz: 시간대 정보.
data_type: 요청한 데이터 유형, "TIMESERIES"로 시간에 따른 관심도를 의미.
검색 관심도 데이터
interest_over_time: "마티니"라는 키워드에 대한 시간에 따른 관심도 데이터.
timeline_data: 각 주차에 대한 검색량
date: 해당 주의 날짜 범위.
timestamp: 해당 날짜의 Unix 타임스탬프.
values: 검색 쿼리와 관련된 값.
query: 검색 쿼리.
value: 해당 기간 동안의 검색량. 이 값은 0에서 100 사이의 점수로, 100은 가장 높은 관심도를 나타낸다.
extracted_value: value의 숫자 표현.
따라서 이 데이터들 중에서, 내가 진행하는 프로젝트에서 필요한 데이터는 data , query, value 값이다.

API 요청을 보냈기 때문에 월 제공량이 0 /100 에서 1/ 100 이 되었다...ㅠㅠ
일단 API 요청 및 응답에 성공했고, 다음엔 이 응답문을 내 프로젝트에서 사용하기 위해 Parsing 하고, DTO 로 옮겨담아 DB 에 저장하거나, View 에서 사용할 수 있는 자료구조로 만드는 작업을 해야겠다.
'Project > 개인 Project' 카테고리의 다른 글
| [Project] 칵테일 추천 알고리즘 설계 - 기본 추천 알고리즘 - (0) | 2025.03.24 |
|---|---|
| [프로젝트] Naver API 응답을 DTO로 변환하여 프로젝트에 사용하기 (1) | 2025.01.21 |
| [프로젝트] SerpAPI + SpringBoot 로 Google Trend API 응답을 서버에서 활용하기 (0) | 2025.01.16 |
| 💡[프로젝트 아이디어] 구글 키워드 검색 API 활용 (Python, SpringBoot) (0) | 2025.01.10 |
| 🐳 Docker 의 localStack 을 활용한 AWS S3 업로드메서드 테스트코드 작성하기 (2) | 2024.12.06 |