1. 기존 Project 에서의 키워드 검색 API 활용 방식
현재 진행 중인 프로젝트에서, 특정 키워드의 검색량 변화를 바탕으로, 검색량의 증가가 가장 많은 키워드를 사용자 화면에 전달하도록 설계 및 구현 하고 있었다.
좀 더 자세히 설명하자면, 네이버 데이터랩 에서, 통합검색어 트랜드 API 를 활용해서, 특정 칵테일의 이름을 검색한 검색량을
2개월 단위로 받아오고, 전전달과 전달의 검색량의 차이를 계산해서, 검색량이 많아진 칵테일 5개를 DB로 저장하는 방식이였다.
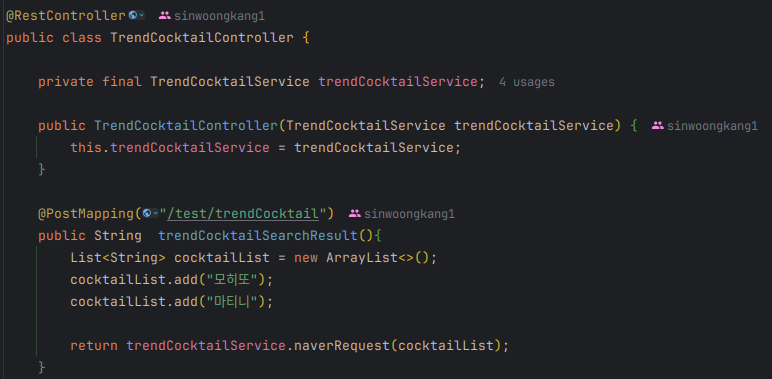
의존성 주입을 받은 trendCocktailServece 인스턴스는 키워드가 저장된 List 자료구조를 인자로 넣으면, API 요청문을 Naver 데이터랩에 전송하고 응답을 반환하는 메서드 naverRequest 를 사용할 수 있다. (요청 메서드 본문은 네이버 데이터랩의 공식문서를 참조하여 작성해 놓음.)
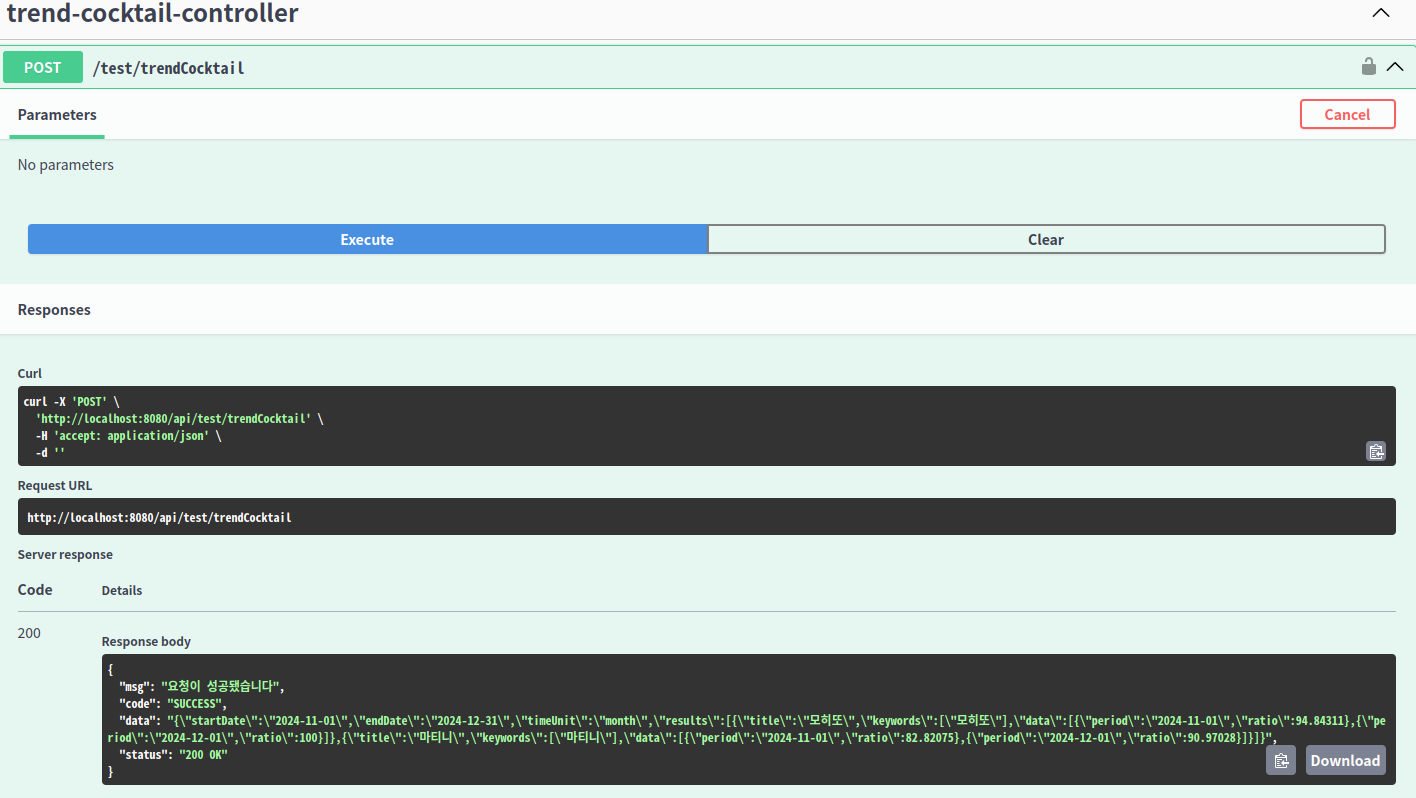
SpringBoot 를 실행하고, Swagger UI 를 통해, 요청에 대한 응답이 잘 반환되는지 확인해보면, 시험 삼아 만든 자료구조 List 에
키워드로 모히또, 마티니를 요청으로 전송한 결과가 전전월, 전월에 대비한 데이터 변화량(ratio)을 반환하는 것을 볼 수 있다.
* ratio 는 전월의 검색량을 100으로 간주하여, 해당 월의 검색량을 추론해볼 수 있다.
즉 ratio 가 90% 면, 전월에 비해 10% 검색량이 감소했다고 간주할 수 있다.
이렇게 요청에 대한 응답으로 받은 문자열들을 DTO 객체로 변환하고, ratio 값을 기준으로 상위 5개의 키워드만 DB 에 저장하여 사용하는 것이 Project Version 1 의 방법이였다.( ratio 값이 소수 5자리 까지 나와서 순위가 겹치는 상황은 거의 발생하지 않았다.)
2. Version.2 에서의 키워드 검색 업그레이드 아이디어
Version2 프로젝트에는 Version1 에서 해보지 못한, 테스트 코드 작성 및 요청 본문 메서드 리팩토링을 하고 있는데, 같은 백엔드 팀원분께서, Naver 의 API 뿐만 아니라, Google의 API 도 이용하면, 좀 더 객관적인 데이터를 사용하게 되는 것 아닐까? 라는 의견을 제시해 주셨고, 국내 검색량 보다 해외 검색량이 상대적으로 더 많을 것이라고 생각되는 Google 의 키워드 검색량을 사용해 보는 것도 타당하다는 생각이 들었다.
앞으로 추가할 구글 트랜드는
구글에서 제공하는 실시간, 기간 별 인기 검색 키워드 제공 서비스
google search, google news, youtube 에서 추출한 트랜드로 분석해 실시간으로 제공한다.
구글의 방대한 검색량과 더불어, youtube 에서 추출한 트랜드 분석까지 추가된다고 하니, 구글 트랜드 API를 사용한다면, 검색량이 많고 인기가 있는 키워드를 사용한다는 것에 대한 의심은 할 수 없을 것 같다.
3. Google Trend의 구현방법 아이디어
3-1. 구글 트랜드는 공식 API를 제공하지 않지만, 많은 사람들이 사용하는 오픈소스로 Python을 이용한 pytrends 라이브러리가 있다. 이 라이브러리를 사용하여 내가 원하는 키워드의 검색 변화량 2개월치를 받아오고, 그 변화량을 계산해서, 검색어 상승이 가장 높은 5개를 AWS bucket 에 googleTrendSearchVolume.txt 파일로 저장한다.
https://github.com/GeneralMills/pytrends
GitHub - GeneralMills/pytrends: Pseudo API for Google Trends
Pseudo API for Google Trends . Contribute to GeneralMills/pytrends development by creating an account on GitHub.
github.com
3-2. googleTrendSearchVolume.txt 파일을 SpringBoot에서 사용한다.
AWS 의존성을 추가하고, 버킷에 있는 파일을 읽어들이는 메서드를 만든다.
(googleTrendSearchVolume.txt 라는 특정 파일을 상수로 만들어서 해당 파일만 읽도록 설정)
googleTrendSearchVolume.txt 파일의 내용을 쉼표로 구분해서 ArrayList 자료 구조에 담도록 메서드를 만들거나, DB에 저장한다.
3-3. Python 서버에서 googleTrendSearchVolume.txt 를 매월 1일에 만들어 덮어쓰기 할 수 있도록 기능을 추가한다.
SpringBoot 서버 에서도 googleTrendSearchVolume.txt 파일을 매월 1일에 읽을 수 있도록 스케줄 기능을 추가한다.
(Python 서버의 메서드가 먼저 실행되고, 그 다음에 SpringBoot 서버의 메서드가 실행되도록 시차를 준다)
3-4. 대략적인 아이디어 흐름 시각화

3-5. 각종 테스트 케이스 작성하기
1. AWS Bucket 에 있는 googleTrendSearchVolume.txt 의 내용을 읽어오는 메서드
2. googleTrendSearchVolume.txt 내용을 쉼표 단위로 Parsing 하여 DTO 혹은 List 자료구조로 만드는 메서드
3. DB 저장 메서드 및 팀원들이 요청하는 반환 타입에 맞게 자료를 반환하는 메서드
4. 지정한 날짜에 파일을 저장하고(Python), 파일을 읽어오는(SpringBoot) 메서드가 실행되는지 테스트
'Project > 개인 Project' 카테고리의 다른 글
| [Project] 칵테일 추천 알고리즘 설계 - 기본 추천 알고리즘 - (0) | 2025.03.24 |
|---|---|
| [프로젝트] Naver API 응답을 DTO로 변환하여 프로젝트에 사용하기 (1) | 2025.01.21 |
| [프로젝트] SerpAPI + SpringBoot 로 Google Trend API 응답을 서버에서 활용하기 (0) | 2025.01.16 |
| [프로젝트] SerpAPI + SpringBoot 로 Google Trend API 요청하고 응답 받기 (0) | 2025.01.13 |
| 🐳 Docker 의 localStack 을 활용한 AWS S3 업로드메서드 테스트코드 작성하기 (2) | 2024.12.06 |